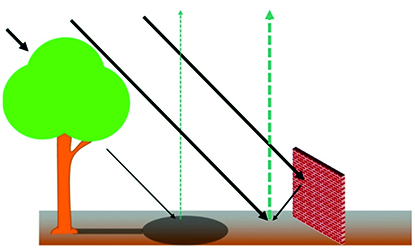
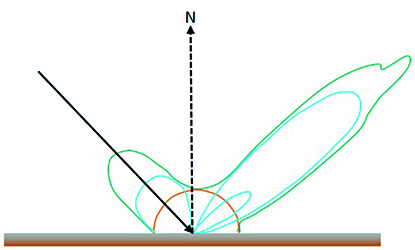
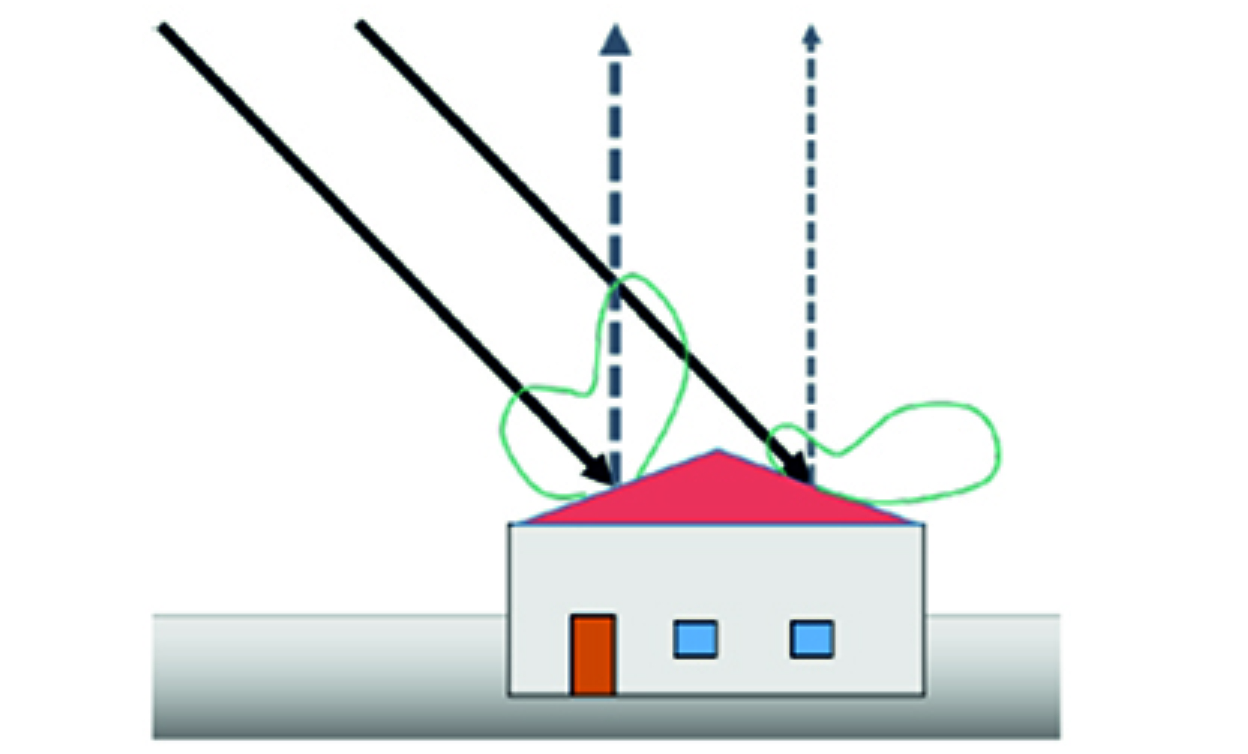
Die Korrektur dieser Effekte ist für eine robuste Datenanalyse erforderlich. Insbesondere beim Vergleich mehrerer Datensätze ist eine einheitliche Darstellung erforderlich. Physikalische Modelle zur Korrektur atmosphärischer Einflüsse werden im Allgemeinen für die Vorverarbeitung von Hyperspektraldaten verwendet. Diese Modelle berücksichtigen jedoch keine lokalen Variationen, wie z. B. Schatten und Objektgeometrie. Daher wurden zusätzlich Ansätze aus den Themengebieten Manifold Alignment und Merkmalsübertragung untersucht, um mehrere Datensätze in ein einheitliches System zu überführen. Bisherige Untersuchungen zu diesen Themen konzentrieren sich hauptsächlich auf das Erlernen der zugrundeliegenden Geometrie der hochdimensionalen Daten und das Alignment mehrerer Datensätze, indem die minimale Diskrepanz ermittelt wird und die individuelle Datenstruktur erhalten bleibt. Normalerweise wird eine einheitliche Domäne mit sehr hoher Dimension gewählt, um das Alignment zu erleichtern. Durch die Transformation in einen anderen Wertebereich wird jedoch die physikalische Interpretierbarkeit verhindert. Außerdem ist die Inversion eines Datensatzes aus der gemeinsamen Domäne in die Domäne eines Zieldatensatzes nur unter bestimmten Voraussetzungen möglich. Beispielsweise muss gezeigt werden, dass ein Urbild der Abbildung für alle Datenpunkte existiert.
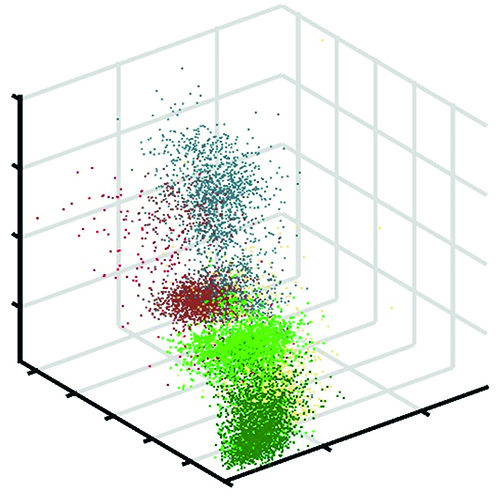
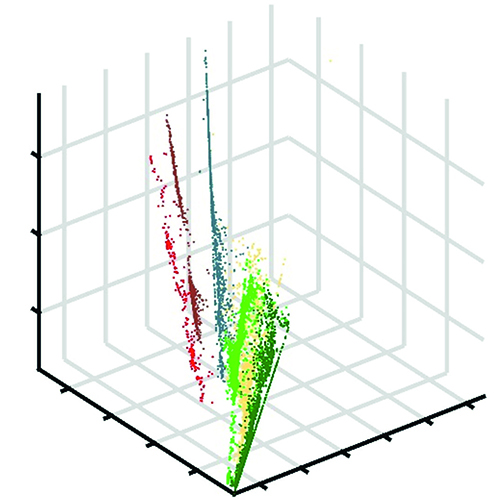
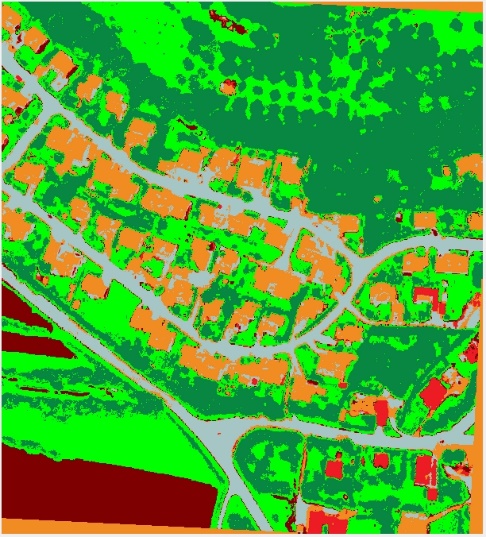
Unser Beitrag zur Problemlösung sind daher zwei Ansätze, die eine gemeinsame Darstellung ermöglichen. Die Nonlinear Feature Normalization (NFN) ist ein datengesteuerter Ansatz zur Abschwächung nichtlinearer Effekte in hyperspektralen Daten. Die NFN ist eine überwachte Methode und erfordert somit Trainingsdaten für jede Klasse in der Szene. Es wird eine neue Basis für die Datendarstellung definiert, die aus einer spektralen Referenzsignatur pro Klasse besteht. Die Trainingsdaten werden anschließend verwendet, um alle spektralen Signaturen individuell in Richtung der neuen Basis zu verschieben. Dies reduziert die Auswirkungen von Nichtlinearitäten signifikant, was durch den Vergleich von Klassifikationsergebnissen vor und nach der NFN-Transformation gezeigt wird.
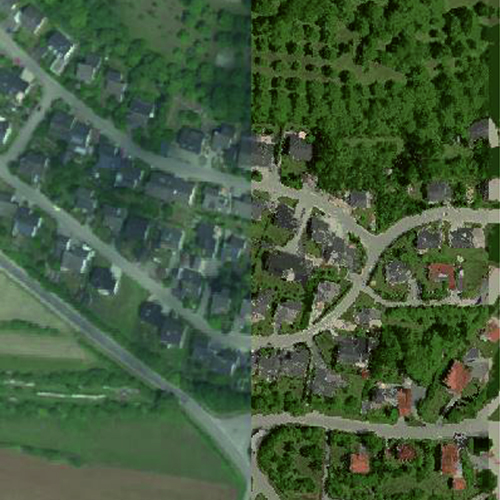
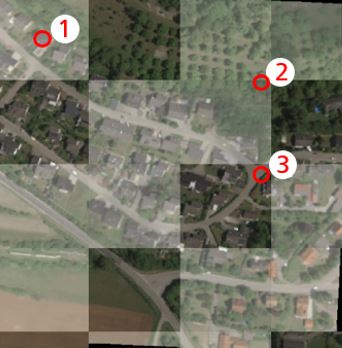
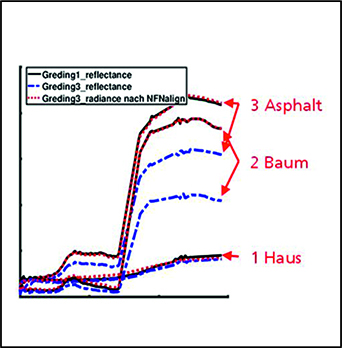
Aus der NFN wird anschließend die Nonlinear Feature Normalization for Data Alignment (NFNalign) abgeleitet. Die NFNalign transformiert mehrere Datensätze zur gleichen Basis und wendet anschließend eine inverse Transformation an, um Datensätze aus der gemeinsamen Domäne in die Domäne eines anderen Datensatzes zu übertragen. Da die Dimensionalität der Daten während der Transformation nicht verändert wird, ist es möglich, die Invertierung analytisch durchzuführen. Die Funktionsweise von NFNalign wird demonstriert, indem hyperspektrale Radianzen in Reflexionsdaten umgewandelt werden. Hierdurch kann der Vorverarbeitungsschritt der Atmosphärenkorrektur ersetzt werden, Schatten und andere Nichtlinearitäten werden korrigiert und charakteristische Merkmale der spektralen Signaturen übertragen. Die Qualität des Alignment wird beurteilt, indem ein auf einem Referenzdatensatz trainiertes Klassifikationsmodell auf den Testdatensatz angewendet wird, nachdem dieser mit NFNalign in die Domäne der Referenz transformiert wurde.