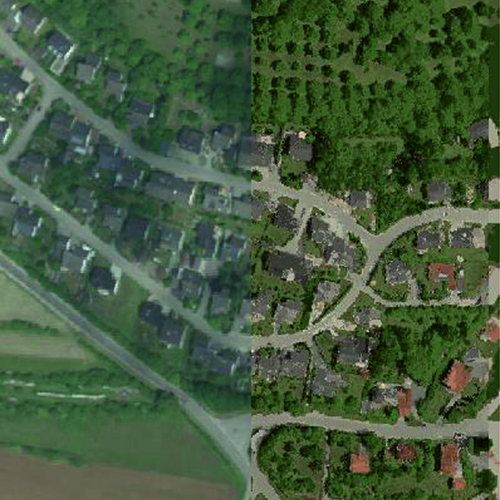
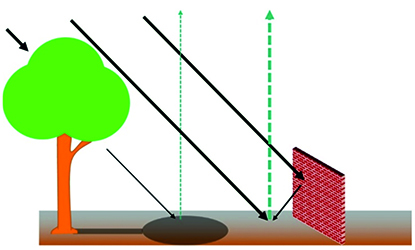
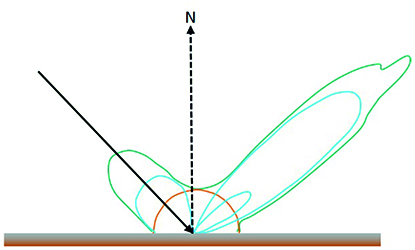
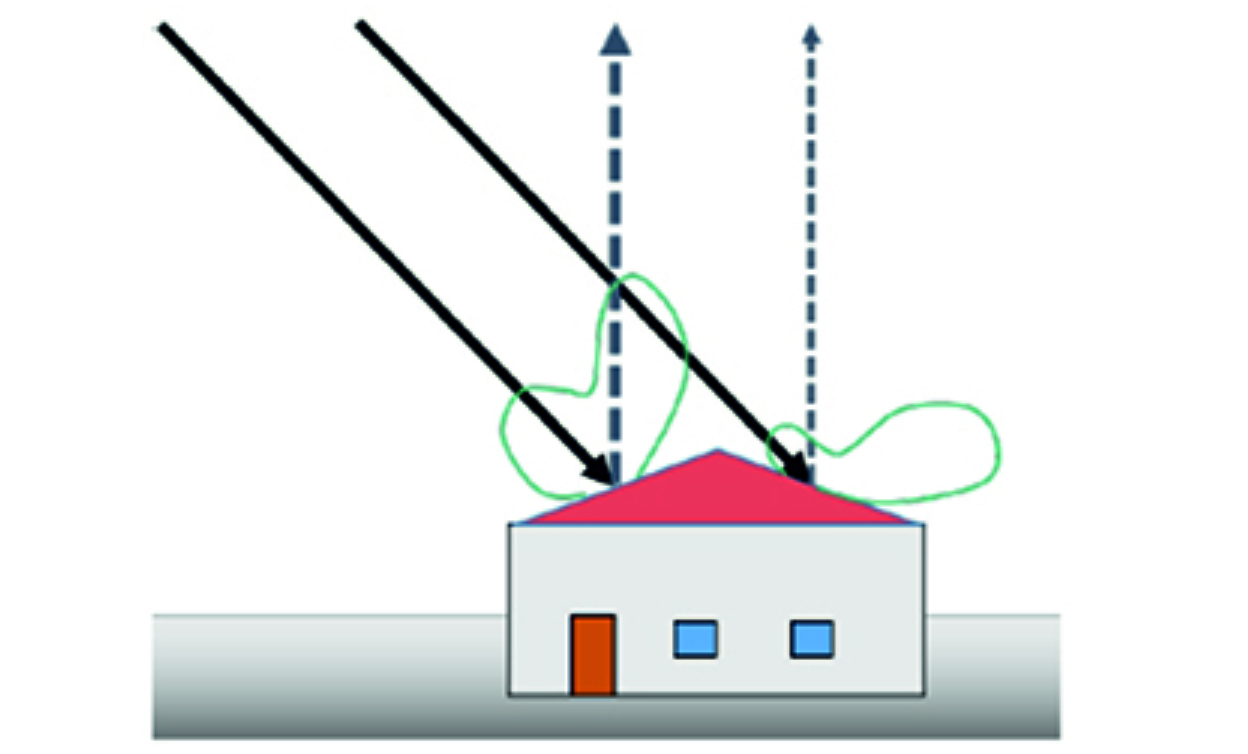
Correcting these effects is necessary for a robust data analysis. Especially when comparing several data sets, a uniform presentation is essential. Physical models for the correction of atmospheric influences are generally used for the pre-processing of hyperspectral data. However, these models do not take local variations into account, e.g., shadows and object geometry. For this reason, approaches from the areas of manifold alignment and feature transfer were also examined to convert several data sets to a common domain. Previous studies on these topics have mainly focused on learning the underlying geometry of the high-dimensional data. The alignment of several data sets is then performed by determining the minimal discrepancy while simultaneously trying to preserve the individual data structure. Usually, a common domain with a very large dimension is chosen to facilitate alignment. However, the physical interpretability can not be preserved by these transformations into another domain. Also, the inversion of a data set from the common domain to the domain of a target data set is only possible under certain conditions. For example, it must be shown that the data set’s pre-image exists for all data points.
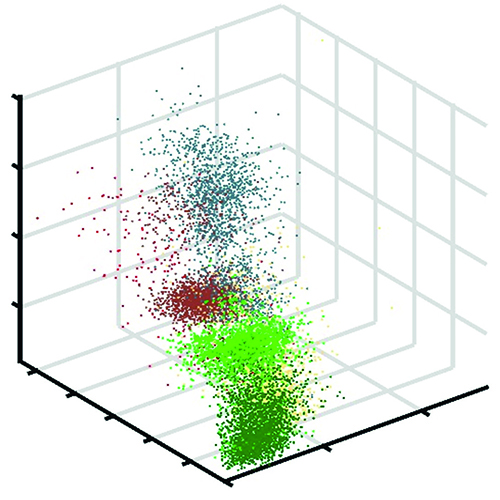
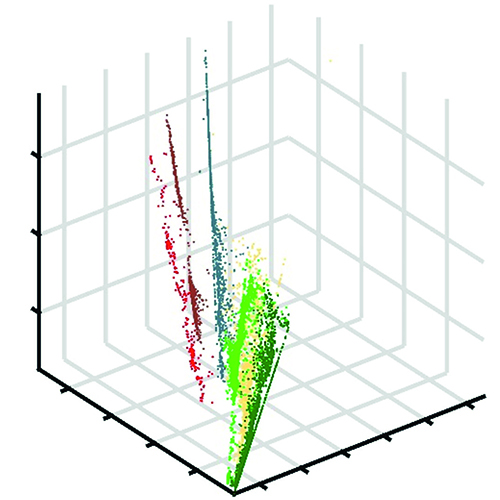
Our contributions to solving this problem are two approaches that enable a common data presentation that is invertible for multiple data sets. The Nonlinear Feature Normalization (NFN) is a data-driven approach to mitigate nonlinear effects in hyperspectral data. The NFN is a supervised method and requires training data for each class in the scene. A new reference system for data representation is defined, which consists of a spectral reference signature for each class in the data set. The training data is then used to shift all spectral signatures towards the new reference system individually. This significantly reduces the effects of nonlinearities, which is shown by comparing classification results before and after the NFN transformation.
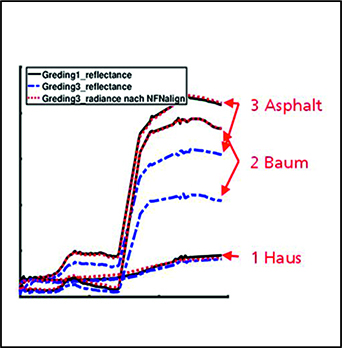
The Nonlinear Feature Normalization for Data Alignment (NFNalign) is then derived from the NFN. The NFNalign transforms several data sets to the same reference system and subsequently uses an inverse transformation to transfer data sets from the common domain to the domain of another data set. Since the dimensionality of the data is not changed during the transformation, it is possible to calculate the inverse transformation analytically. The performance of the NFNalign is demonstrated by converting hyperspectral radiance data to reflectance data. In this way, the pre-processing step of the atmospheric correction can be replaced, shadows and other nonlinearities are corrected, and characteristic features of the spectral signatures are transmitted. The quality of the alignment is assessed by applying a classification model trained on a reference data set to the test data set after it has been transformed into the domain of the reference using NFNalign