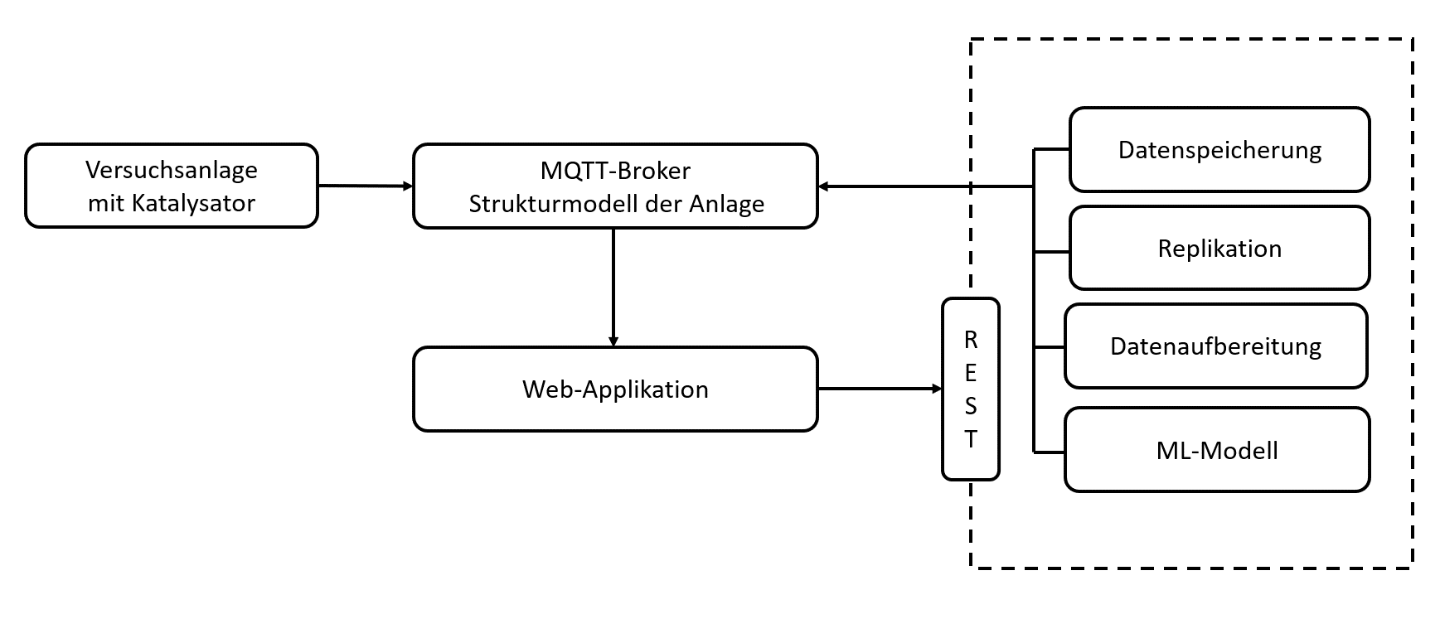
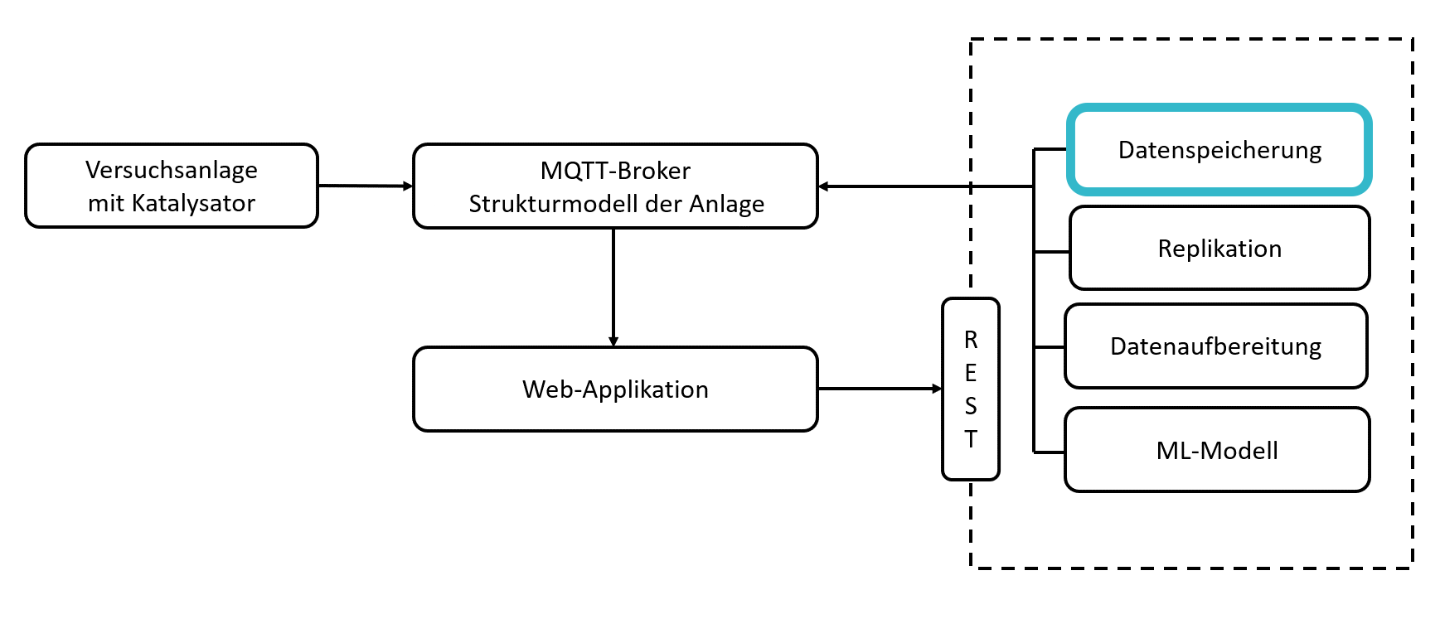
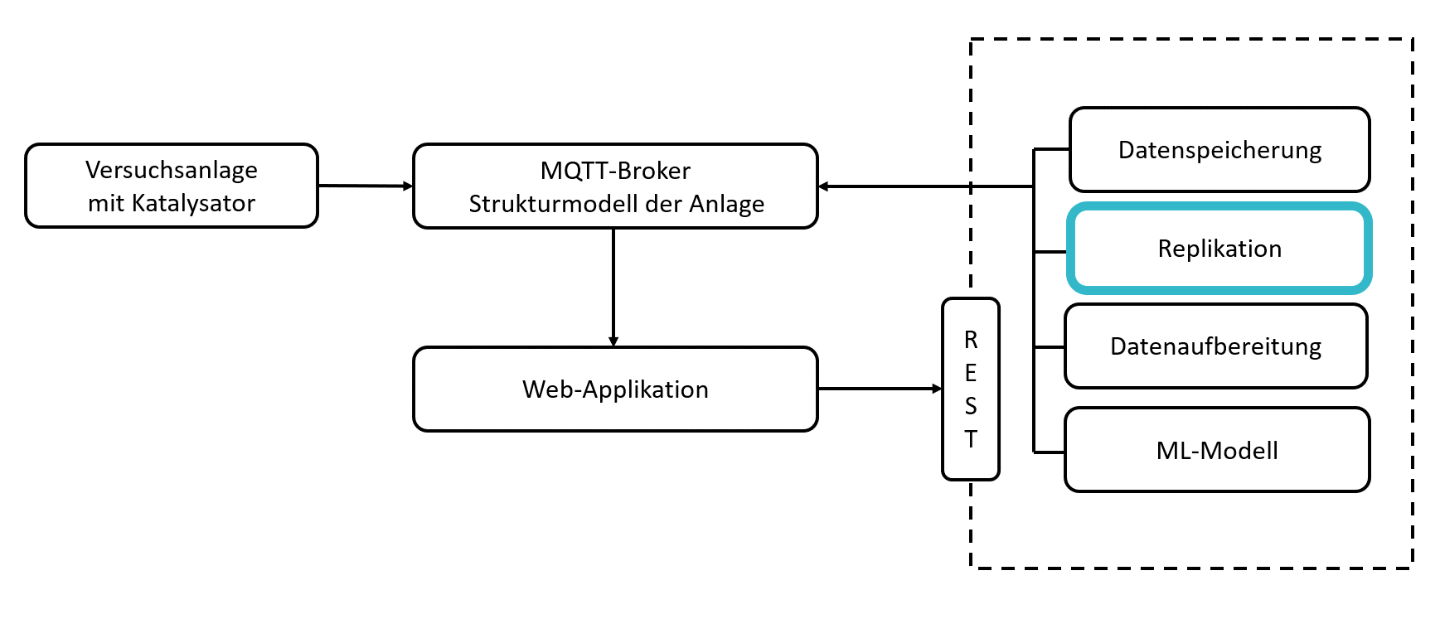
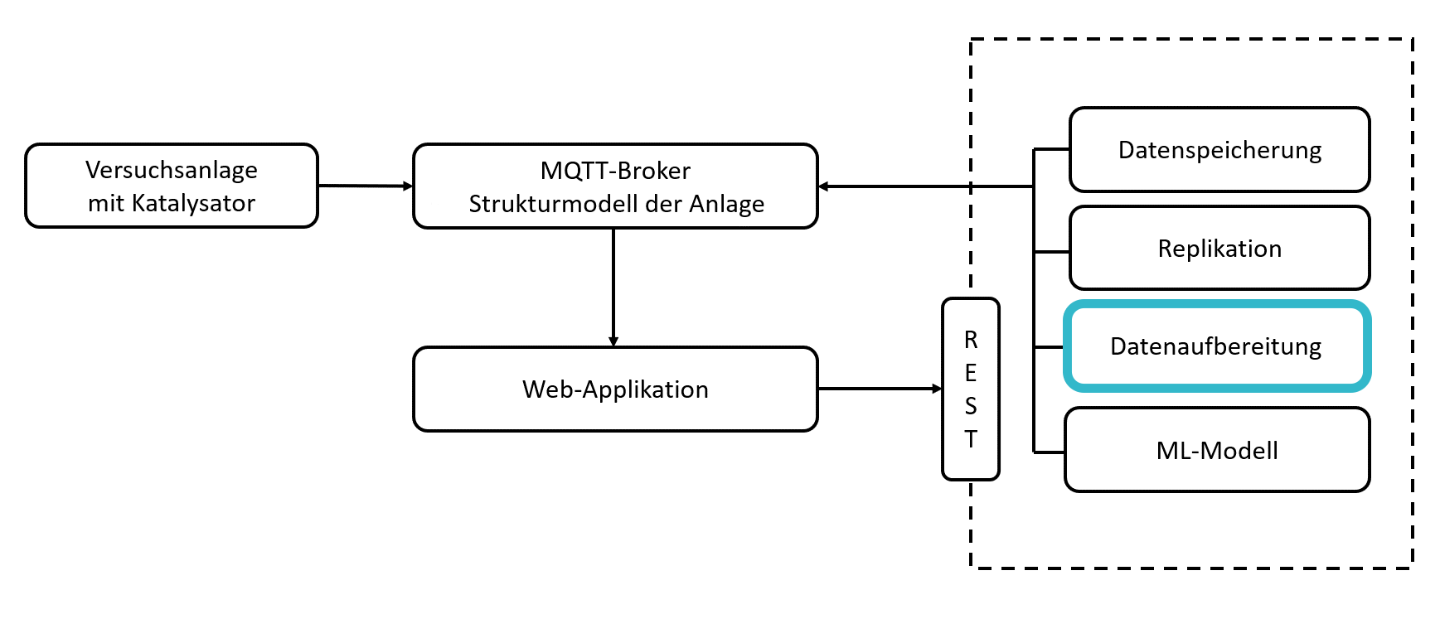
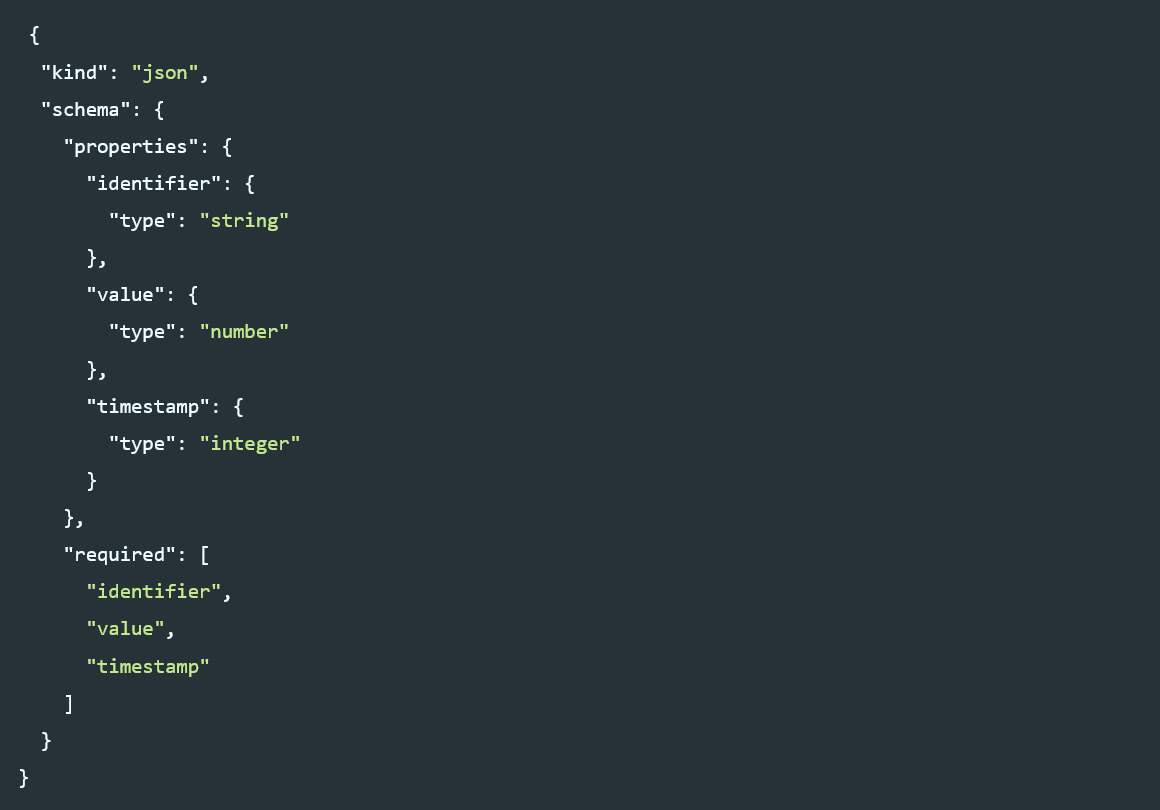
ML4P-Pipelinekomponenten
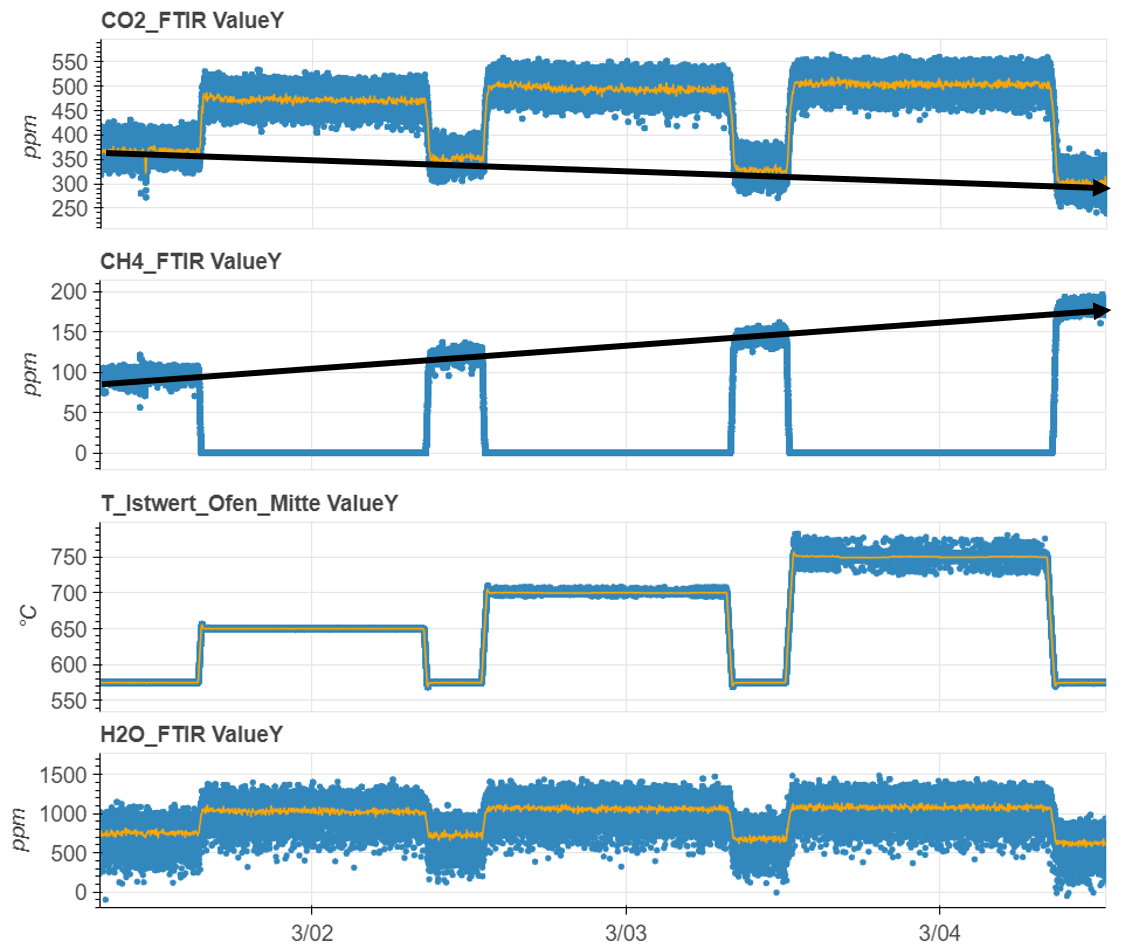
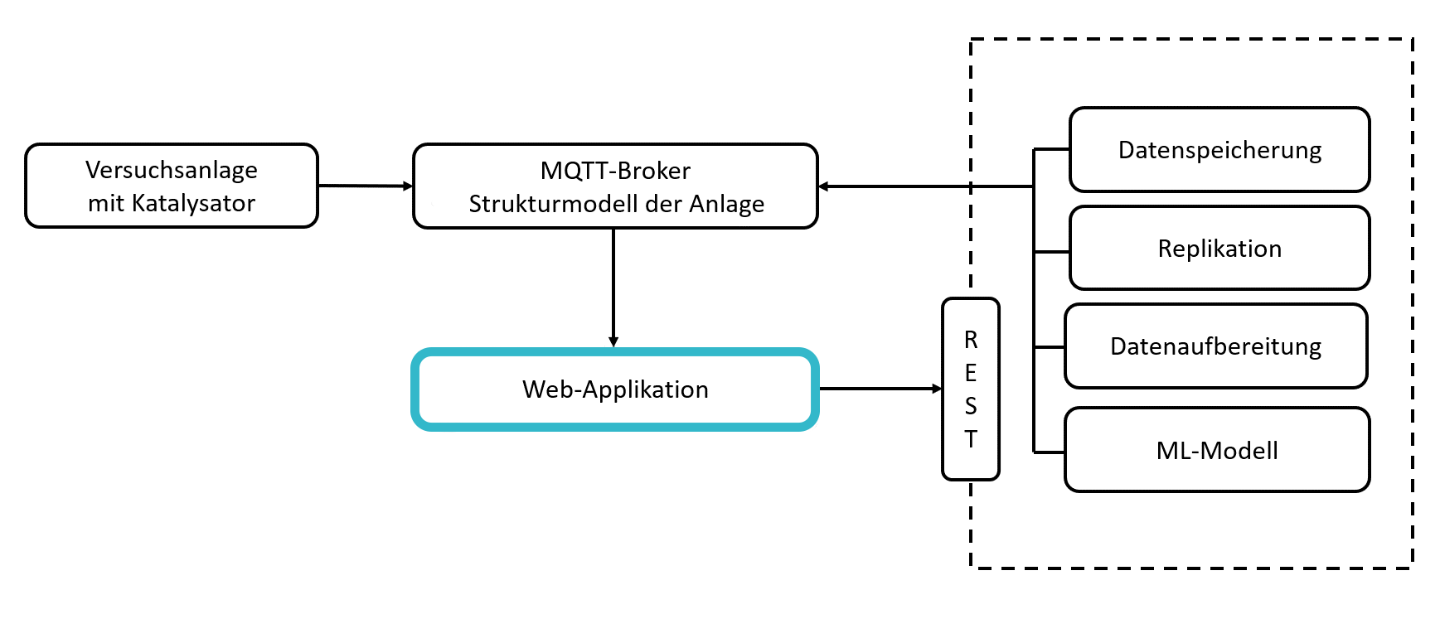
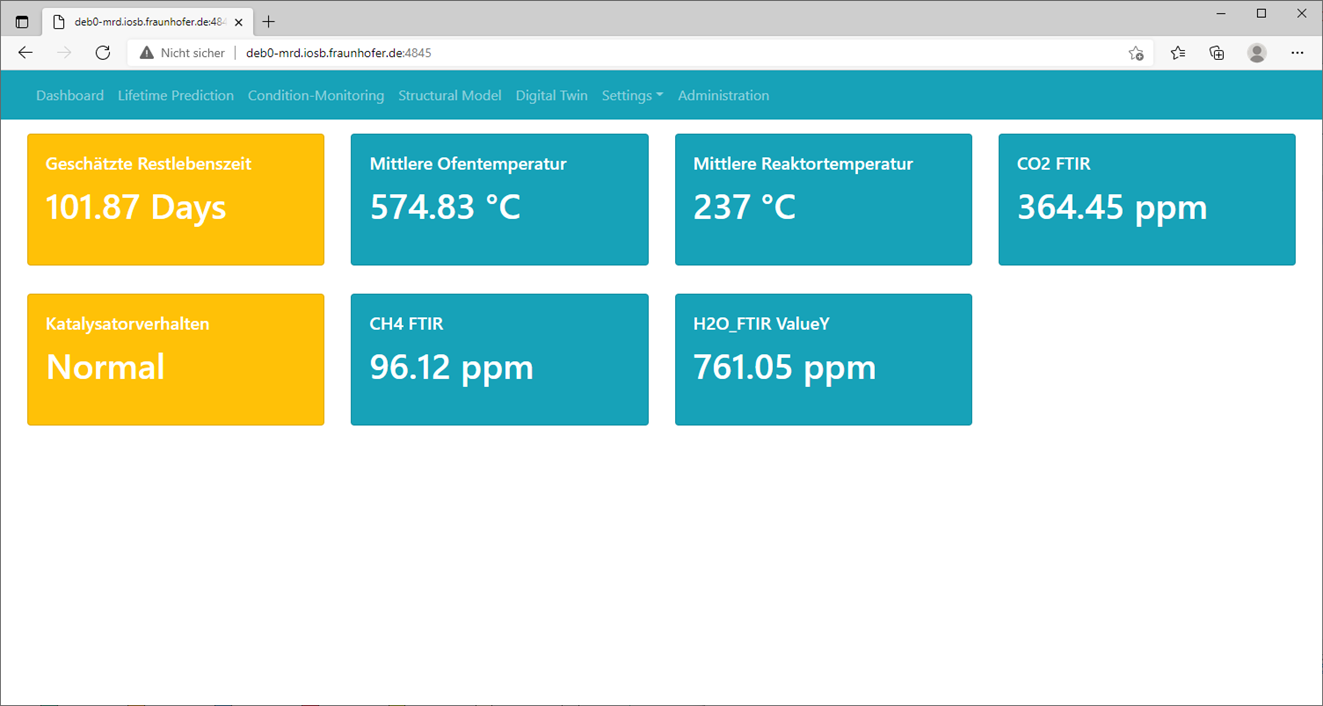
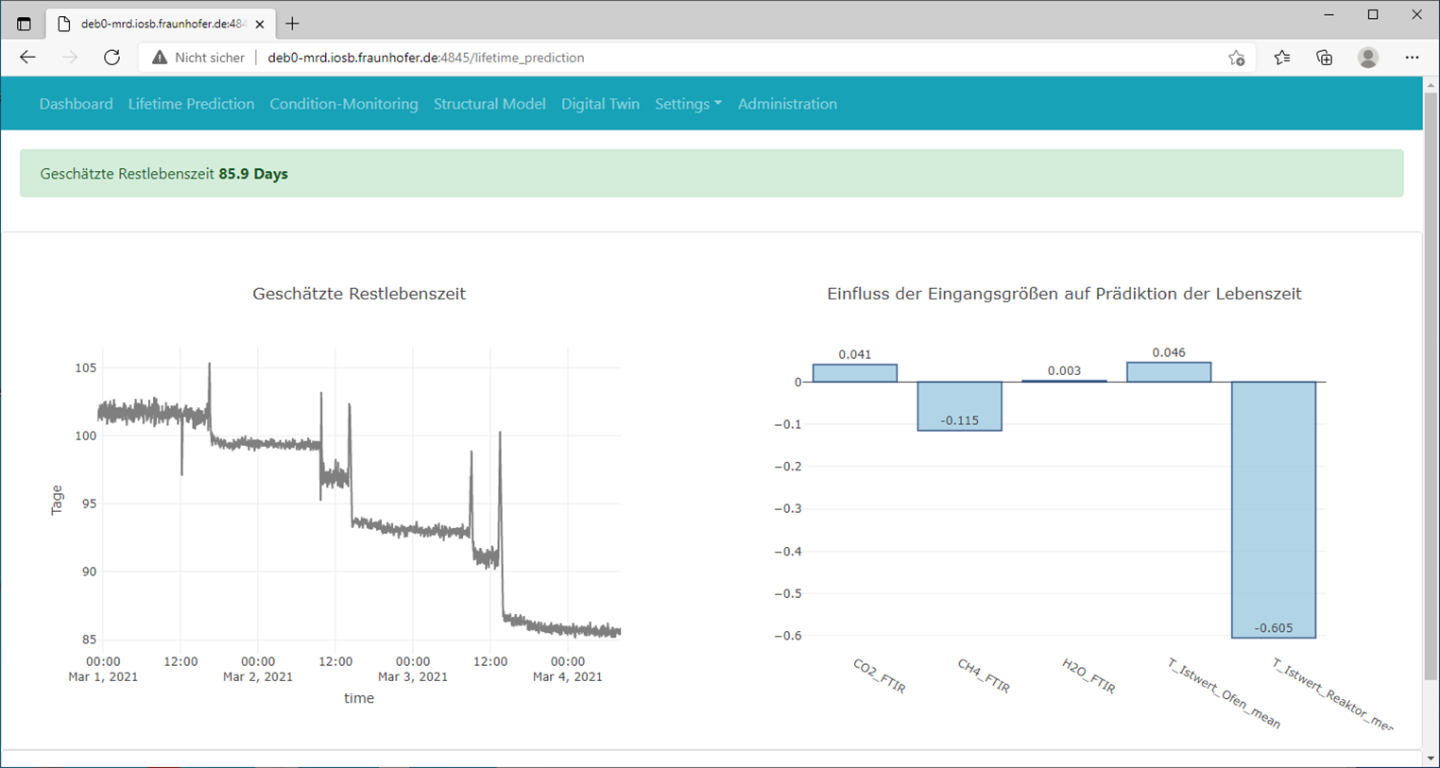
Wie in der Projektzusammenfassung beschrieben, soll das Machine Learning(ML)-Modell im Streamingbetrieb auswerten, wie viel Lebenszeit dem Katalysator noch bleibt, bevor er ausgewechselt werden muss. Das Ergebnis selbst soll dem Nutzer in Form einer Web-Applikation angezeigt werden.
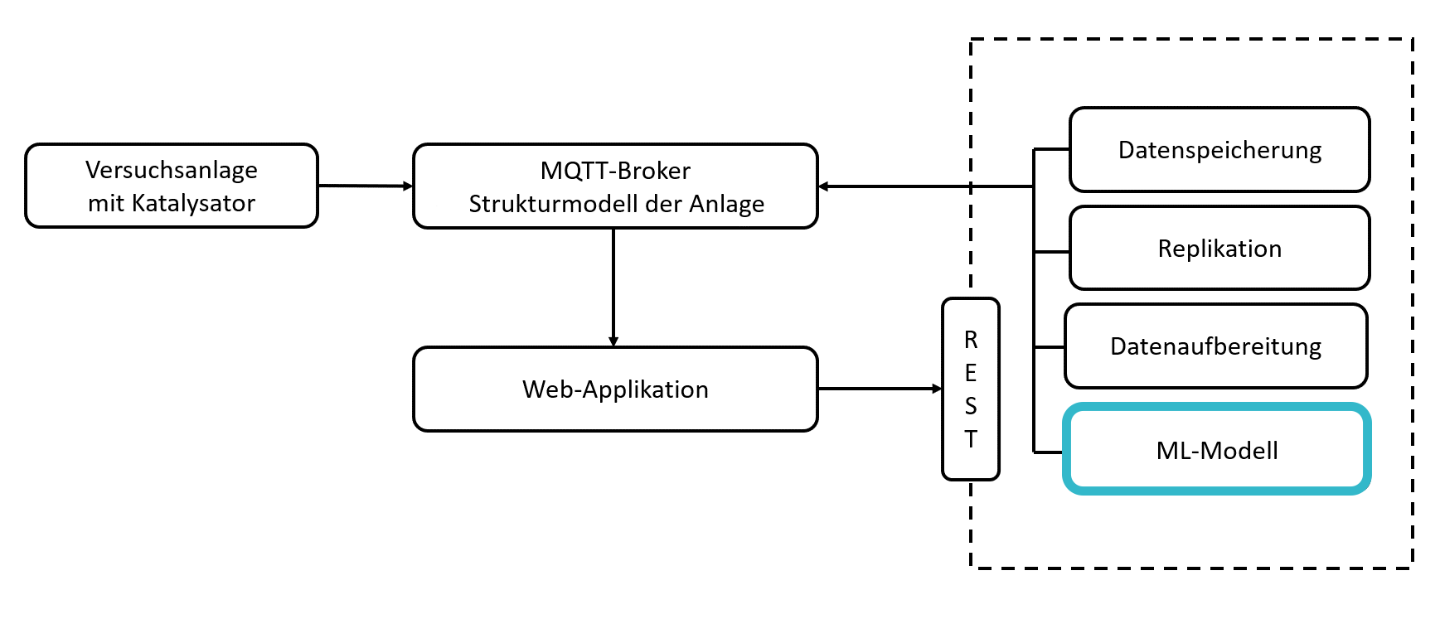
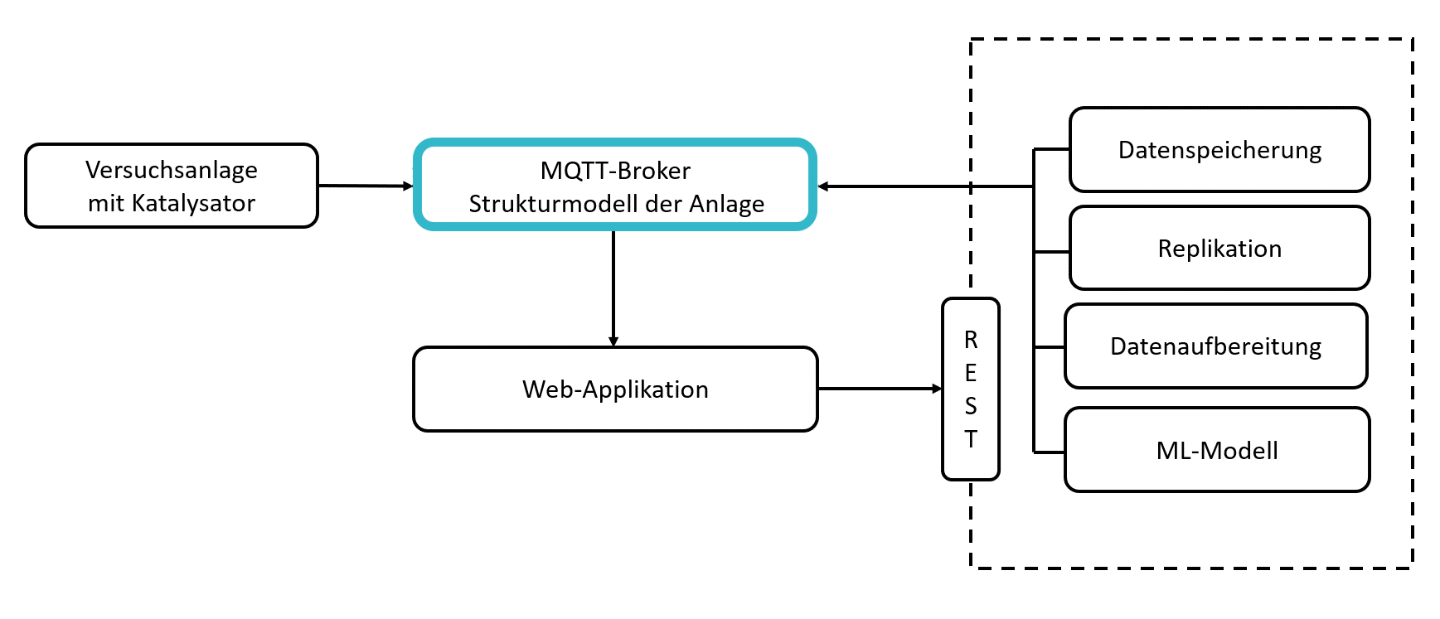
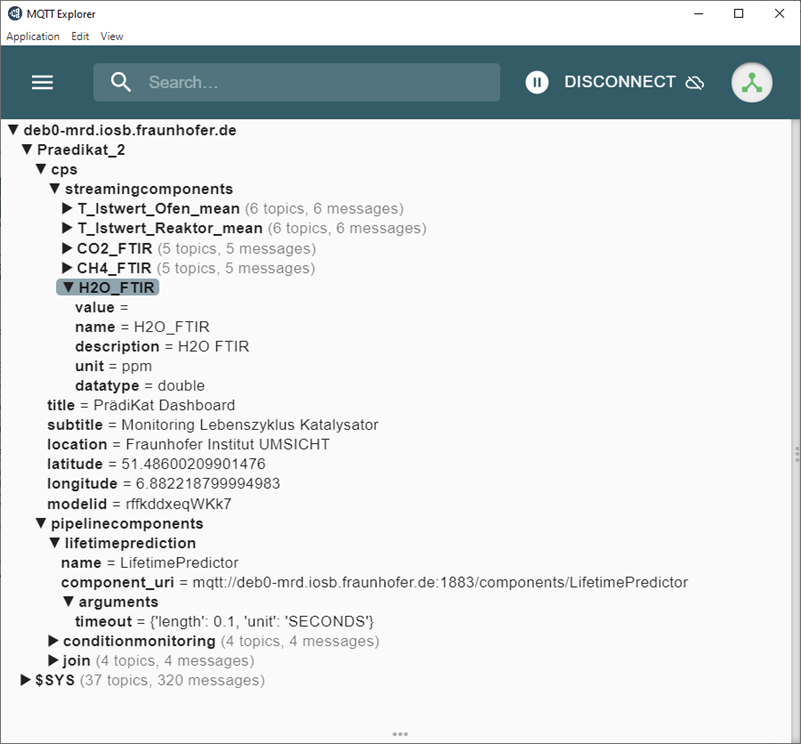
Eine zentrale Rolle nimmt hierbei ein sogenannter »Message Broker« ein. Dieser kann Nachrichten empfangen (z.B. Messdaten der Anlage) und diese an eine weitere Komponente weiterleiten (z.B. ML-Modell). Gleichzeitig muss die Web-Applikation auch auf Nachrichten (z.B. Ergebnis des ML-Modells) zugreifen und visualisieren können. Als Message Broker (Datentransport) wurde für die Applikation »MQTT« (Message Queuing Telemetry Transport) verwendet. Zur Auswertung der Messdaten wurde auf die im Fraunhofer Leitprojekt »ML4P« (engl. Machine Learning for Production, dt. Maschinelles Lernen in der Produktion) entwickelte Datenverarbeitungspipeline zurückgegriffen. Die dort entwickelte Software bietet die Möglichkeit, Komponenten zur Datenerfassung, -verarbeitung und -speicherung zu implementieren und über eine REST Schnittstelle zu starten, zu stoppen oder zu aktualisieren. Mithilfe der entwickelten Web-Applikation lassen sich Daten vom Message Broker abrufen und darstellen sowie einzelne Komponenten der ML4P-Verarbietungspipeline ansprechen.