

Motivation
"Data is the raw material of the 21st century". This sentence, which has often been heard, is particularly true for medical data for two reasons. On the one hand, medical data are of enormous importance for penetrating previously little studied or understood contexts. On the other hand, they must first be obtained for their later use. Data in the health care sector is often distributed in different IT systems and there is a lack of uniform interfaces. Moreover, many of the data formats used are outdated, proprietary and not very interoperable. However, for a target-oriented and sustainable use of the data, they must be prepared and made accessible at a central location.
Solution
For this purpose, the Fraunhofer IOSB offers Wolverine, a collection of coordinated and extended components that support the integration and evaluation of medical data. To achieve a maximum degree of interoperability, Wolverine relies on established international standards wherever possible. The core of the system is HAPI FHI, the flexible open source implementation of the HL7 FHIRstandard. This is extended by application-specific modules that import data from practice information systems (Praxisinformationssystemen; PVS), laboratory information systems (Laborinformationssystemen; LIS) or other data sources, for example. The data sources determine which methods are required for processing. The bandwidth ranges from direct database queries to AI-based text mining on unstructured data objects (e.g. doctors' letters). The data integrated in this way is described during import by established semantic standards such as LOINC- or ICD-codes.
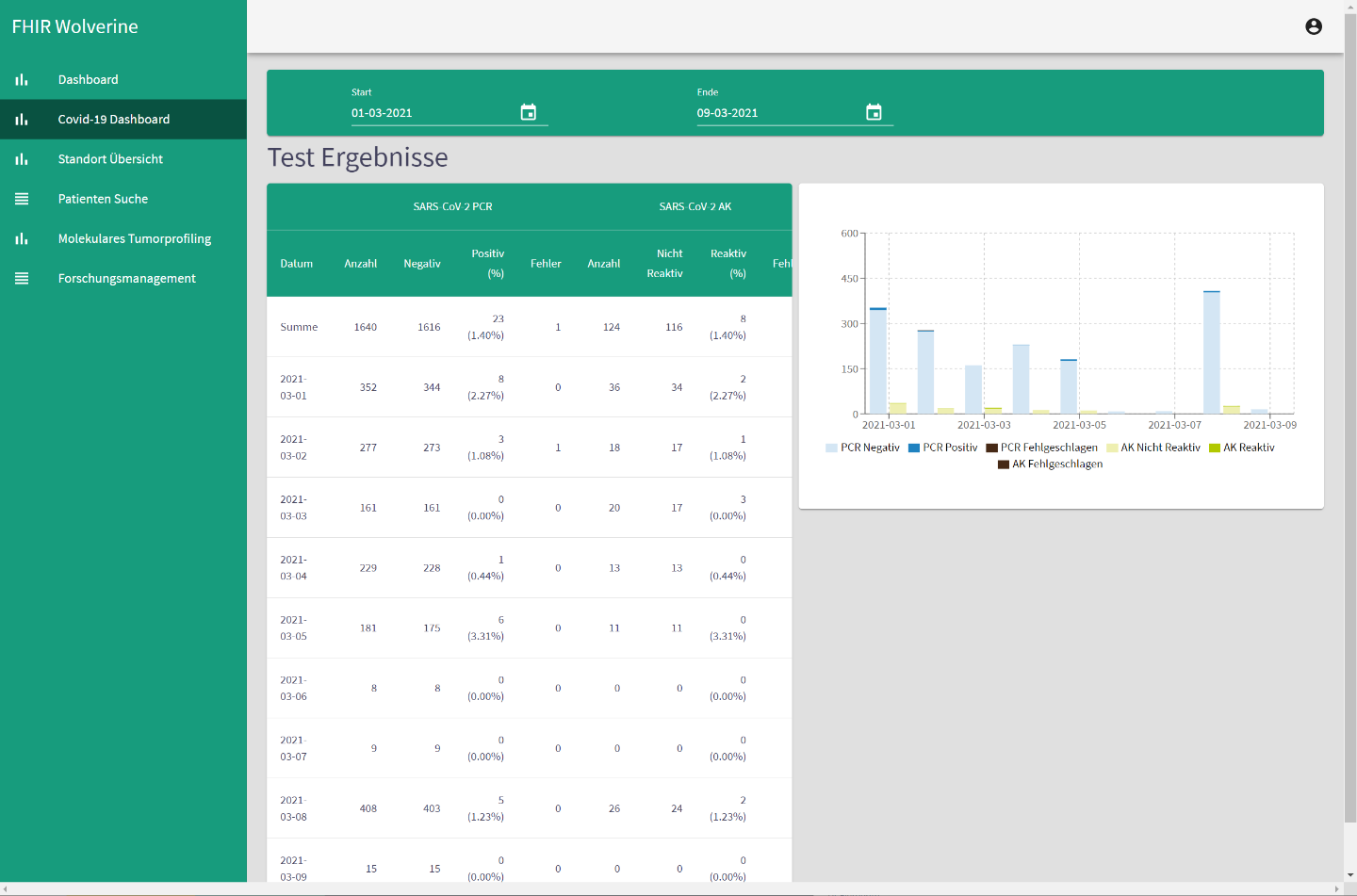
Once the medical data has been collected at a central location, it is available for targeted user-driven analyses. Simple statistical analyses are automatically performed by the system itself and are available in the individually expandable dashboard. Patients can also be automatically informed about completed analyses and, if necessary, retrieve them via a secure website. For complex analyses, data can also be accessed directly via the REST interface of the FHIR server. To ensure data protection, the data for the respective analyses can be made available anonymously or pseudonymized as an option on the basis of an authorization concept.