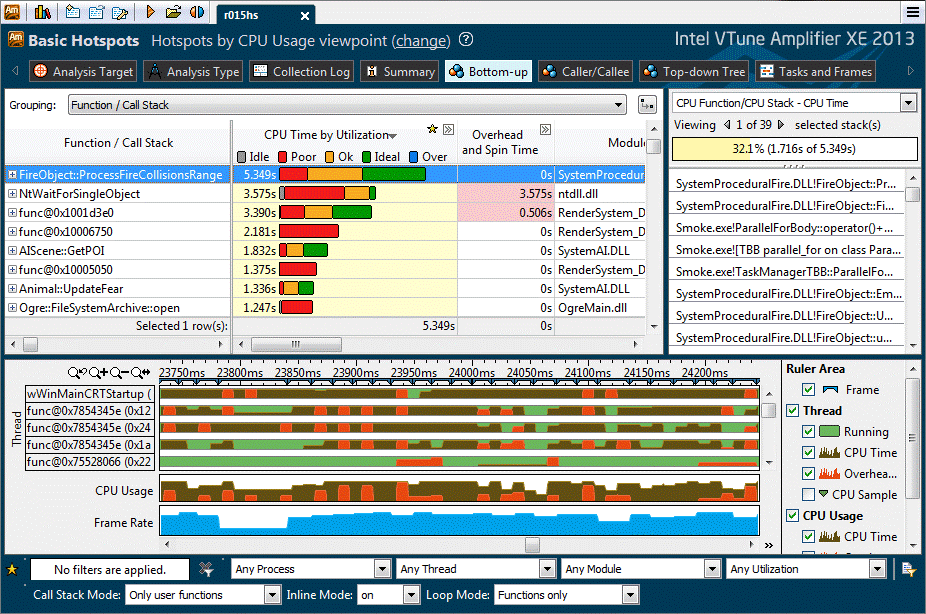
Our research group concentrates on a variety of interesting problems in hardware architecture and programming environments for various processors. We perform research in the field of parallel processing, which covers the following tightly coupled areas:
1) The processor architecture
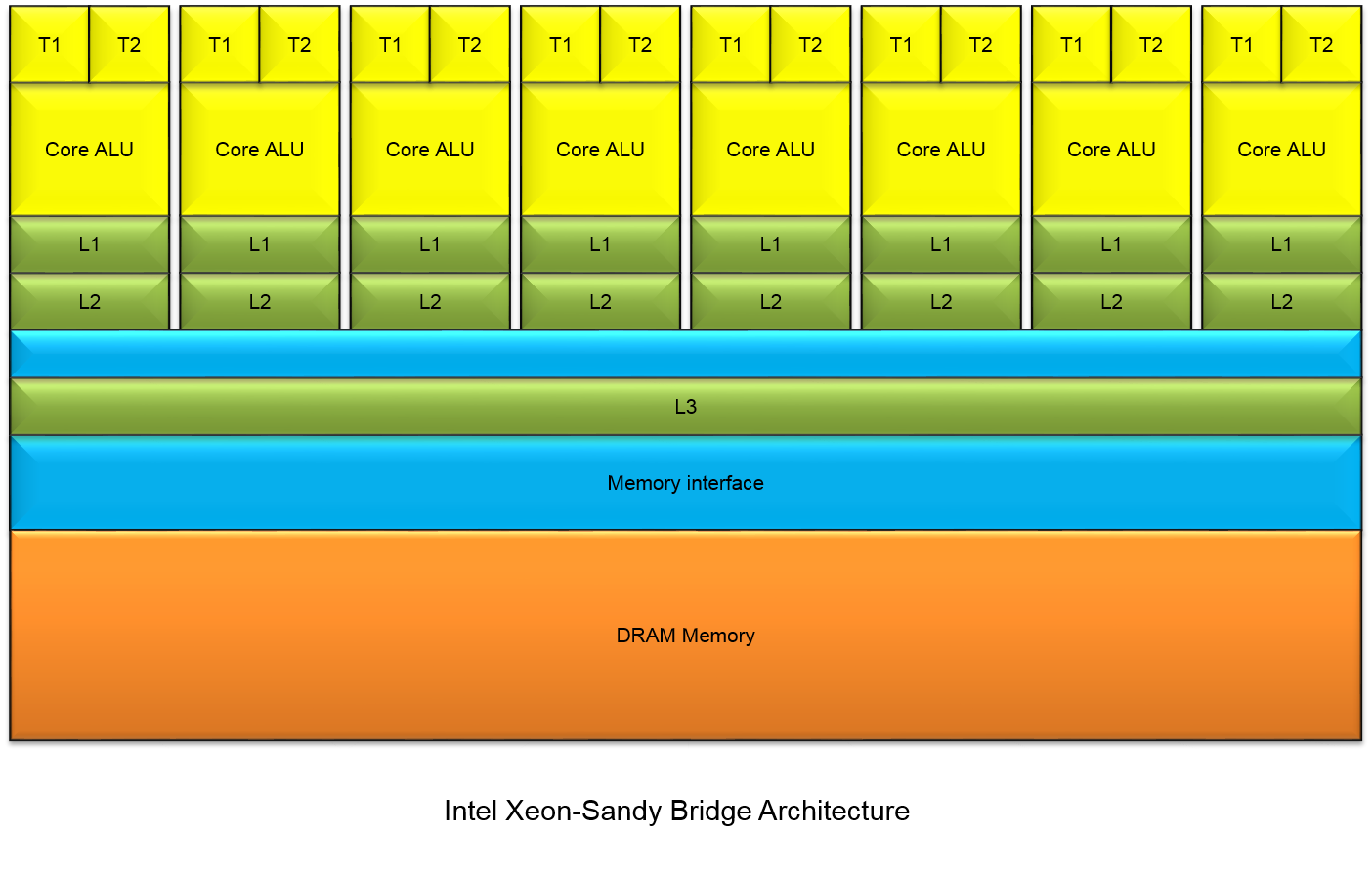
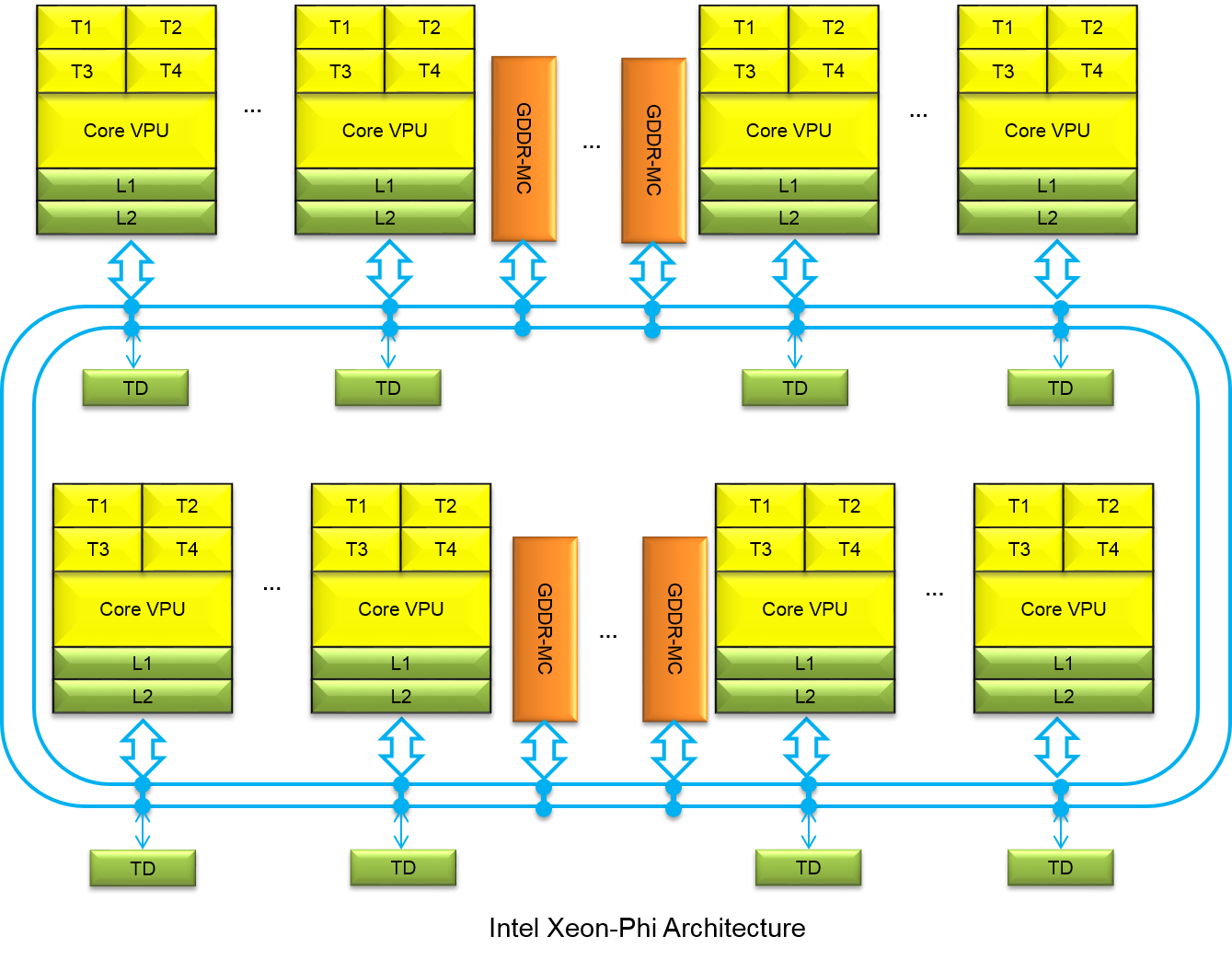
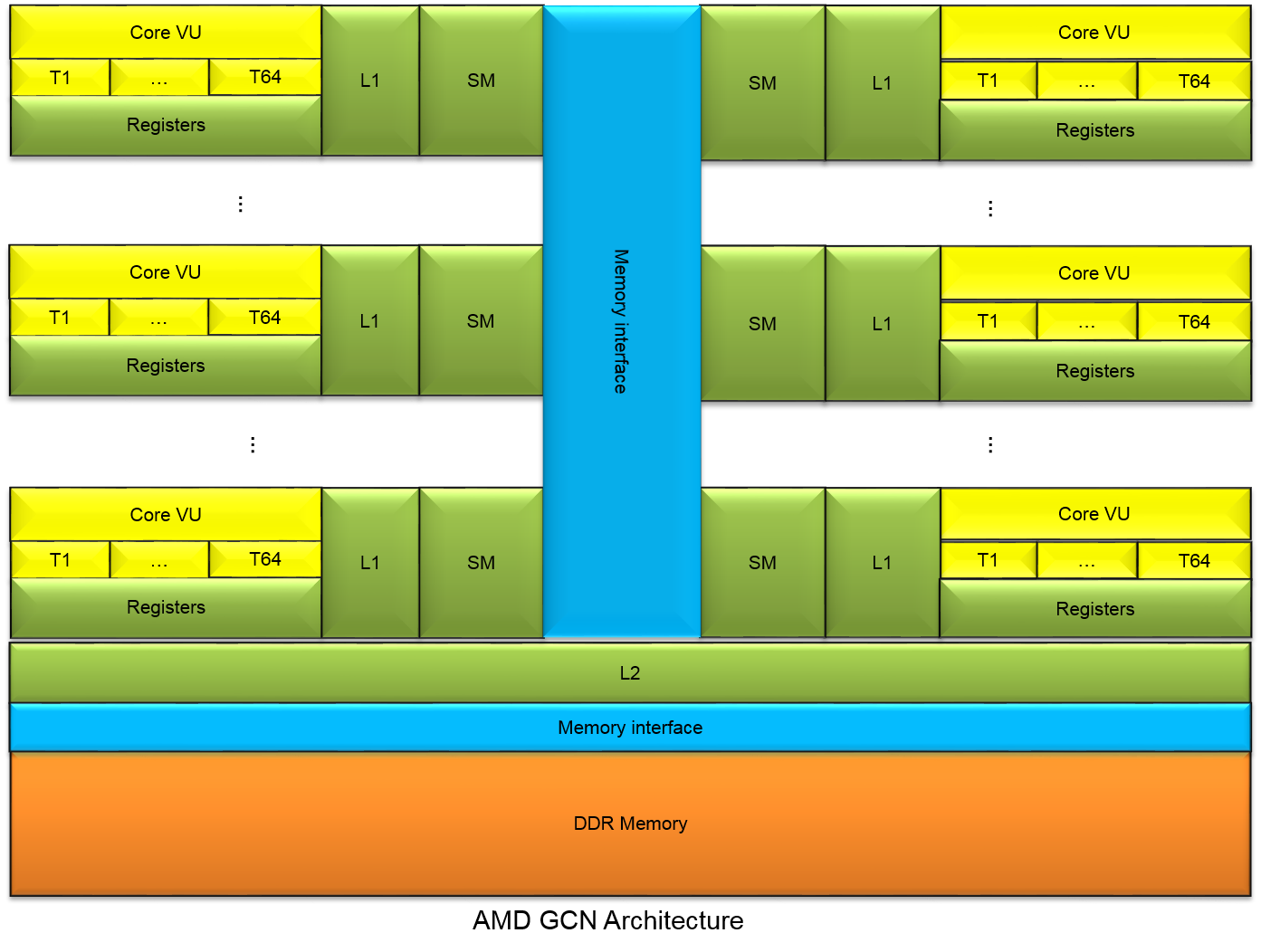
We focus our research on topics such as: accelerators (GPUs, FPGAs and specialized processors like Intel ® Xeon Phi ™) and instruction set architectures (x86 microarchitecture extensions AVX, SSE). Recently, we have been particularly interested in the use of graphic cards for general-purpose computation also known as GPGPU. Historically, GPUs have used fixed-function logic to implement the graphics pipeline. However, the increasing demand for programmability from industry has led to easily programmable GPUs, that can be used to efficiently implement many algorithms.
2) Architecture-aware mapping of applications
One of our major research efforts is the investigation of machine vision algorithms and data structures on various co-processor hardware. The variety of different platforms spans a wide spectrum of optimization methods and a large set of different algorithmic transformations. We investigate various optimization-transformation techniques to get most out of the hardware architecture. One piece of recent work concentrates on the parallel implementation of image feature extraction on GPUs and CPUs:
Konrad Moren, Diana Göhringer and Thomas Perschke, “Accelerating Local Feature Extraction using OpenCL on Heterogeneous Platforms”, DASIP 2014, Madrid, October 2014.
3) The code analysis and tuning process for parallel architectures
The typical machine vision application consists of many separate tasks. The workload of those tasks can vary dramatically with algorithmic complexity and input size. From the programmer perspective, it is very difficult to map those tasks to different processor architectures. The problem which we are most interested in, is how to build an efficient runtime-system that has a high performance and automatically adapts to flexible hardware platforms. Within this field we are investigating programming environment-models like OpenCL, compilers and their suitability for accelerators.